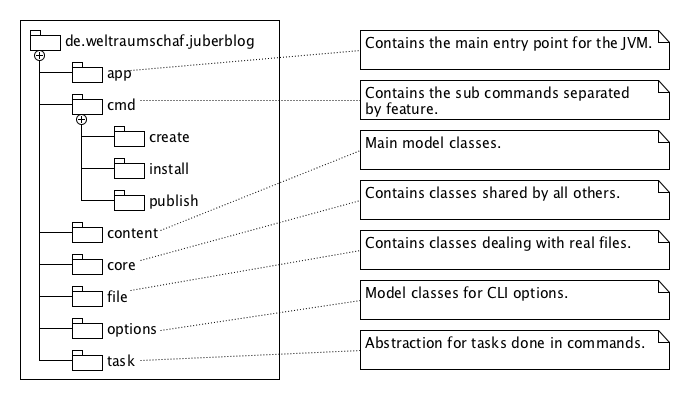
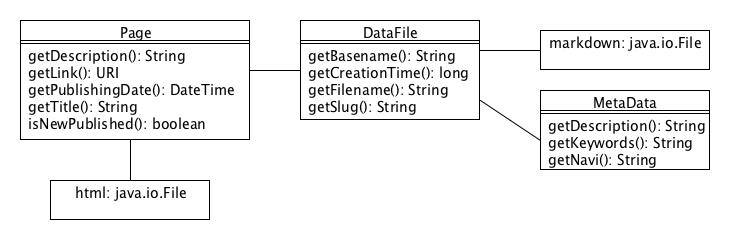
Here you find a more detailed explanation of the basic concept behind JUberblog and some details about the implementation.
The publishing concept is very simple: The publish command crawls a configured directory for Markdown files and converts them to static HTML in a web servers document root. So that’s all. Nearly.
What about versioning? No database at all? No, no database. In my opinion it make no sense to structure non-relational data like documents into a relational database scheme. Especially if I have to reassemble it from the tables back to a document on each page request. Then adding caching and such. Why not saving documents as is: A document. In a file.
I’ve chosen the Markdown syntax for the files because it is more readable and easier to maintain than pure HTML. Also I’ve added some basic template features (see below). And last but not least, if You really want versioning: Use Git or any other VCS for the directory where you save your Markdown files for the blog. Then you will have full-blown version features with diff and so on.
Ok, version is done by a VCS. What about automatic publishing of new posts? Easy going: Just use a system like cron or atd and at a periodic execution which runs the publisher.
The basic publishing concept is shown in the image below:
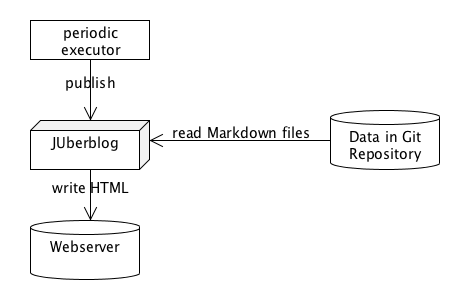
What does this show?
That’s all.
Of course you can imagine various scenarios:
The pure blog data is stored in plain text files in Markdown syntax with some useful extensions (see Pegdown Processor for details) and an optional preprocessor block for meta data. The format is as follows:
<?juberblog
// Used for navigation.
navi: Projects
// Used for site description.
description: My personal projects I'm working on
// Used for site keywords.
keywords: Projects, Jenkins, Darcs
?>
## The Headline
Lorem ipsum dolor sit amet, consetetur sadipscing elitr,
sed diam nonumy eirmod tempor invidunt ut labore et dolore
magna aliquyam erat, sed diam voluptua. At vero eos et
accusam et justo duo dolores et ea rebum. Stet clita kasd
gubergren, no sea takimata sanctus est Lorem ipsum dolor
sit amet.
Lorem ipsum dolor sit amet, consetetur sadipscing elitr,
sed diam nonumy eirmod tempor invidunt ut labore et dolore
magna aliquyam erat, sed diam voluptua. At vero eos et
accusam et justo duo dolores et ea rebum.
Meta data in data files are stored in a pre processor block (separated by <?juberblog and ?>). Inside these blocks the pre processor recognizes simple key value pairs.
NL = [ '\r' ] '\n' ;
ALPHA = 'a' .. 'Z' ;
NUM = '0' .. '9' ;
ALNUM = ALPHA | NUM ;
metadata = '<?juberblog', NL, { key_value_pair NL }, '?>' ;
comment = '//' [^NL]* NL ;
key_value_pair = key, ':', value ;
key = ALNUM { ALNUM } ;
value = ANY_WORD, NL ;
You can add key values what you like. All key values from the pre processor will be assigned as variables to templates. But the these special ones are used internally for content generation:
The primary part is obviously Markdown generation which is done by the Pegdown library. But soon it was obviously that simple templating mechanics are necessary. For this I chosen Freemarker.
The basic idea is we have simple text files which are rendered from Markdown to HTML. This HTML is inserted in some HTML template which layouts the content. And at least this HTML snippet will be inserted into an outer layout template which is shared across all generated HTML. Here comes the template engine into play.
While integrating Pegdown and Freemarker it emerged that that I need additional features:
These are very generic concerns which are not strictly bound to JUberblog so I decided to extract this into a separate library: FreeMarkerDown. See the FreeMarkerDown architecture site for detailed information how it works.